

Every user, from the data scientist training a massive language model to the home user booting up a decade-old PC, shares a common frustration: performance degradation.
This slowdown is often attributed to software bloat, operating system updates, or malware, but the true culprit frequently lies deeper, rooted in the physical limitations and inevitable degradation of the hardware itself.
Software can only ever be as fast as the silicon, copper, and glass it runs upon [1].
The moment a component fails to deliver data, power, or processing speed at its peak capacity, the entire system suffers a performance hit that no amount of code optimization can fully resolve.
This analysis embarks on a journey through the history of computing performance issues, viewed strictly through the lens of hardware.
We will start at the bleeding edge, examining the exotic and extreme challenges faced by the most advanced systems in the world—AI supercomputers and exascale data centers.
We will then transition to the modern mainstream, discussing the common, everyday hardware pitfalls that plague consumer and enterprise machines.
Finally, we will take a critical look at the legacy systems, where the physics of aging and mechanical wear created unique and often catastrophic performance problems.
The central thesis is that performance loss is not a random event, but a constant battle against the physics of degradation and limitation, a battle that spans all eras of computing.
The Future is Hot: Performance Challenges in Advanced AI and Exascale Hardware
The world of advanced computing, dominated by artificial intelligence (AI) and high-performance computing (HPC), operates at the very limits of physics.
Here, performance bottlenecks are measured in nanoseconds and are often the result of exotic hardware architectures designed to push the boundaries of data throughput.
The issues in this domain are not about simple failure, but about the inability of one component to keep pace with the exponential growth of another.
The AI Accelerator Crisis: GPUs, TPUs, and Specialized Silicon
The core of modern AI is the accelerator—typically a Graphics Processing Unit (GPU) or a Tensor Processing Unit (TPU).
These chips are compute-rich, but their performance is increasingly constrained by the speed at which they can access the vast amounts of data required for training large models.
Memory Bandwidth Bottlenecks (HBM)
The most critical bottleneck in AI hardware today is the memory wall, specifically the gap between the speed of the processing core and the speed of the memory that feeds it [2].
High Bandwidth Memory (HBM) was developed to address this.
HBM uses a revolutionary 3D-stacked architecture, placing memory dies directly on the same interposer as the GPU, providing unparalleled data transfer rates—often measured in terabytes per second (TB/s) [3].
However, even HBM is now considered a bottleneck.
As AI models, particularly Large Language Models (LLMs), grow in size, developers immediately build larger models to fill the available memory, ensuring that memory bandwidth remains the limiting factor [4].
The physical proximity of HBM to the processor also creates a thermal challenge.
The intense heat generated by both the compute core and the memory stacks must be managed, and any failure in the complex cooling system immediately triggers thermal throttling, a hardware-enforced slowdown that can cripple a multi-million-dollar training run.
Inter-Chip Communication (NVLink, InfiniBand)
Distributed AI training requires multiple accelerators to work in concert, sharing model parameters and gradients across a cluster.
This necessitates ultra-low-latency, high-bandwidth interconnects.
NVLink and InfiniBand are the dominant technologies here, and their saturation is a major performance saboteur [5].
NVLink provides extremely high bandwidth (up to 1.8 TB/s in some generations) for communication between GPUs within a single server node.
InfiniBand, on the other hand, excels at scalable, low-latency networking between different server nodes [6].
When the data transfer rate between these chips or nodes cannot keep up with the processing speed, the GPUs become data-starved.
They sit idle, waiting for the next batch of data to arrive, effectively reducing the cluster’s efficiency and throughput.
This “data-starvation” problem is a direct hardware issue—a limitation of the interconnect fabric—that translates into massive performance loss and wasted compute cycles.

High-Speed Storage and Data Pipelines
The storage subsystem in an AI data center is no less critical.
The move from traditional hard drives to Non-Volatile Memory Express (NVMe) Solid State Drives (SSDs) has been essential, but it has introduced new, subtle performance issues.
PCIe Lane Saturation
Modern GPUs and NVMe drives all rely on the PCI Express (PCIe) bus to communicate with the CPU.
In high-density servers, the number of available PCIe lanes from the CPU is a finite resource that must be shared among multiple high-bandwidth devices.
This leads to PCIe lane saturation [7].
For example, a server might have four GPUs, each requiring 16 lanes (x16), and several high-speed NVMe drives.
If the CPU only provides 64 lanes, the devices must share, often forcing a GPU to run at x8 speed or less.
While some workloads show minimal impact, deep learning and content creation tasks can see significant performance loss—up to 58% in some content creation workflows—when PCIe bandwidth is reduced [8].
This is a fundamental hardware allocation problem that must be meticulously managed to avoid performance bottlenecks.
NVMe Write Amplification and Wear
While NVMe drives are orders of magnitude faster than their predecessors, they are not immune to degradation.
The performance of an SSD is intrinsically linked to its finite lifespan, governed by the physics of NAND flash memory.
Every write and erase operation causes microscopic degradation to the cell’s oxide layer [9].
To manage this, SSD controllers use a process called garbage collection and wear leveling.
When data is updated, the controller must write the new data to a fresh block, erase the old block, and then update the mapping table.
This process results in write amplification (WA), where the actual amount of data written to the flash memory is a multiple of the data the host system intended to write [10].
High WA leads to increased internal write traffic, higher latency, and a reduction in the drive’s overall throughput, effectively slowing down the system as the drive ages and fills up.
This is a silent, hardware-level performance killer that is particularly acute in data centers with constant, heavy write loads.
The Cost of a Cache Miss
At the most granular level, the performance of any processor, including an AI accelerator, is governed by its CPU cache.
A cache is a small, ultra-fast memory pool located directly on the chip.
When the processor needs data, it checks the cache first.
A cache hit (finding the data) is fast, costing only a few clock cycles.
A cache miss (not finding the data) is devastating, forcing the processor to wait for data to be fetched from the much slower main memory (DRAM), costing hundreds of CPU cycles [11].
In the context of massive AI datasets, cache misses are more likely to occur because the data required exceeds the cache’s capacity [12].
The performance impact is immediate and severe: the processor sits idle, waiting for data, leading to a massive loss of potential execution time.
This is a hardware design issue—the physical size and organization of the cache—that directly dictates the efficiency of the software running on it.
The Everyday Grind: Performance Degradation in Modern Consumer and Enterprise Hardware
Moving from the exotic world of supercomputing to the everyday reality of modern desktop PCs, laptops, and standard enterprise servers, the performance issues become less about pushing physical limits and more about maintenance, thermal management, and component wear.
These are the silent saboteurs that slowly choke the life out of a system over its three-to-five-year lifespan.
CPU and GPU Thermal Management
The single greatest enemy of sustained performance in a modern system is heat.
Both CPUs and GPUs are designed to run at high clock speeds, but they are also programmed with thermal limits.
Once these limits are exceeded, the hardware initiates thermal throttling, reducing the clock speed and voltage to prevent physical damage.
This is a hardware-enforced performance reduction that is often caused by simple, preventable maintenance issues.
Thermal Paste Degradation
The interface between the processor’s Integrated Heat Spreader (IHS) and the cooler’s cold plate is a thin layer of thermal paste.
This paste is designed to fill the microscopic air gaps between the two surfaces, which are poor conductors of heat.
Over time, due to repeated heat cycles, the paste degrades—it dries out, cracks, or “pumps out” from the center [13].
As the paste degrades, its thermal conductivity plummets, creating an insulating layer that traps heat on the processor die.
This leads to higher operating temperatures, which in turn causes the CPU or GPU to hit its thermal limit sooner and more frequently.
The result is a system that cannot maintain its boost clocks, leading to lower performance in gaming, rendering, and other demanding tasks [14].
Replacing the thermal paste every few years is a simple, yet critical, maintenance step to restore peak performance.
Voltage Regulator Module (VRM) Overheating
The Voltage Regulator Modules (VRMs) on a motherboard are responsible for taking the input voltage from the power supply and converting it into the precise, stable, and lower voltages required by the CPU and RAM.
These components work incredibly hard, especially under heavy load or during overclocking, and they generate significant heat.
If the VRMs overheat, the motherboard’s firmware will often trigger a protective measure, which can manifest as a sudden and severe CPU throttle [15].
This throttling is often mistaken for a CPU issue, but it is the motherboard’s power delivery hardware failing to cope with the demand.
Poor VRM cooling, often due to inadequate heatsinks or poor case airflow, means the CPU cannot draw the power it needs to maintain its clock speed, leading to a performance bottleneck that is entirely hardware-centric.
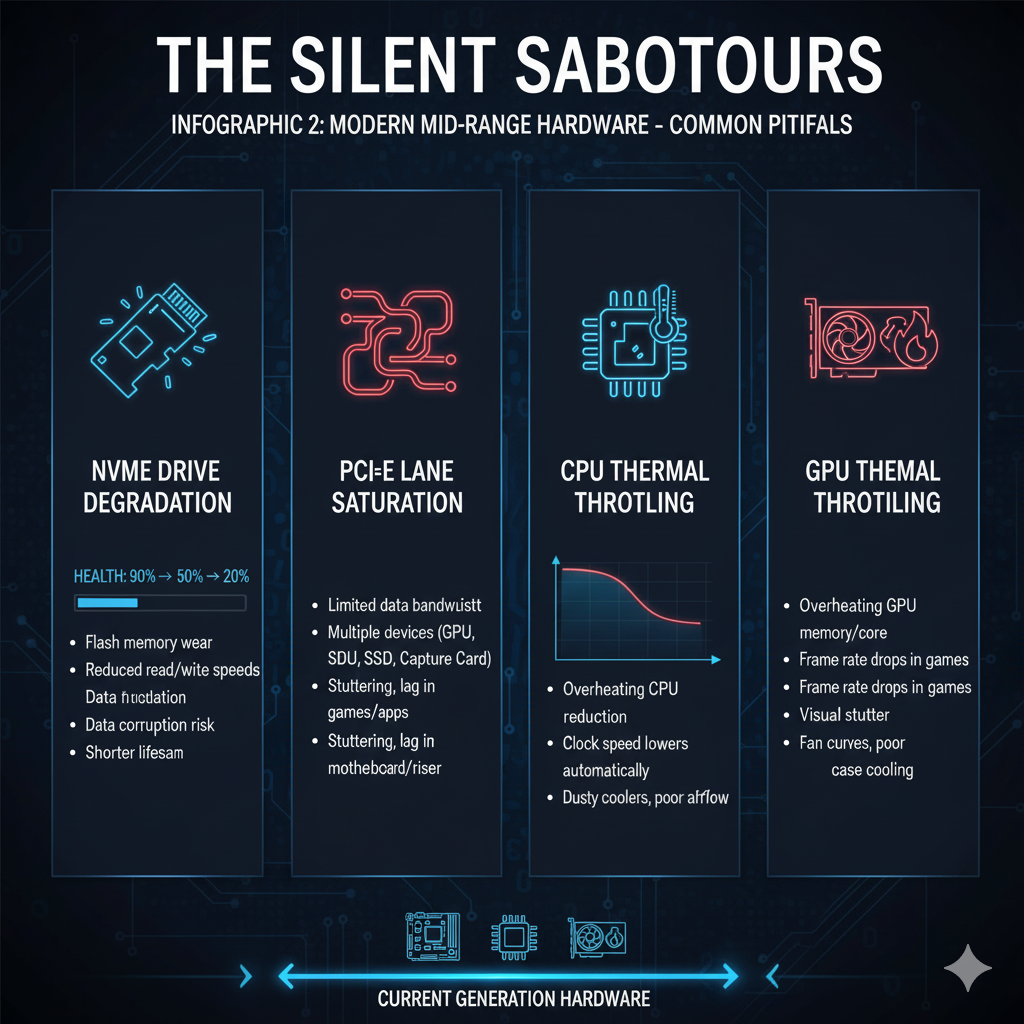
The Storage Subsystem Evolution
While the modern mainstream has largely adopted SSDs, the performance issues have simply shifted from mechanical wear to flash wear.
SSD Write Amplification and Wear
As discussed in the advanced section, Write Amplification (WA) is a fundamental issue for all NAND-based storage.
In consumer and enterprise SSDs, the performance impact of high WA is most noticeable as the drive fills up and ages [16].
A nearly full SSD has fewer free blocks to use for garbage collection and wear leveling, forcing the controller to work harder and more frequently, which increases WA and reduces write performance and throughput.
The drive effectively slows down, not because of a software issue, but because the physical management of the flash memory becomes more complex and time-consuming.
Memory and Bus Issues
Even the system memory (RAM) and the communication buses can be sources of subtle, yet significant, performance loss.
RAM Timings and XMP/EXPO Profiles: Modern RAM is often sold with speeds higher than the motherboard’s default settings.
To achieve these speeds, users must enable an eXtreme Memory Profile (XMP) or EXPO profile in the BIOS.
If this profile is not enabled, or if the motherboard is incompatible, the RAM will run at a much slower, default speed, causing a major bottleneck for the CPU [17].
This is a configuration issue, but the underlying problem is the hardware’s inability to communicate at its rated speed.
PCIe Slot Issues: A poorly seated graphics card or a dusty PCIe slot can cause the connection to fall back to a lower link speed (e.g., running at x8 instead of x16, or even PCIe 3.0 instead of 4.0).
This physical connection issue reduces the bandwidth between the GPU and the CPU, leading to a performance drop that is difficult to diagnose without specialized tools.
A Trip Down Memory Lane: The Unique Hardware Woes of Vintage PCs
The performance issues of the past were often more dramatic, more mechanical, and more visible.
In the era of the late 1990s and early 2000s, the hardware was less about thermal limits and more about the failure of analog components and the inherent limitations of mechanical systems.
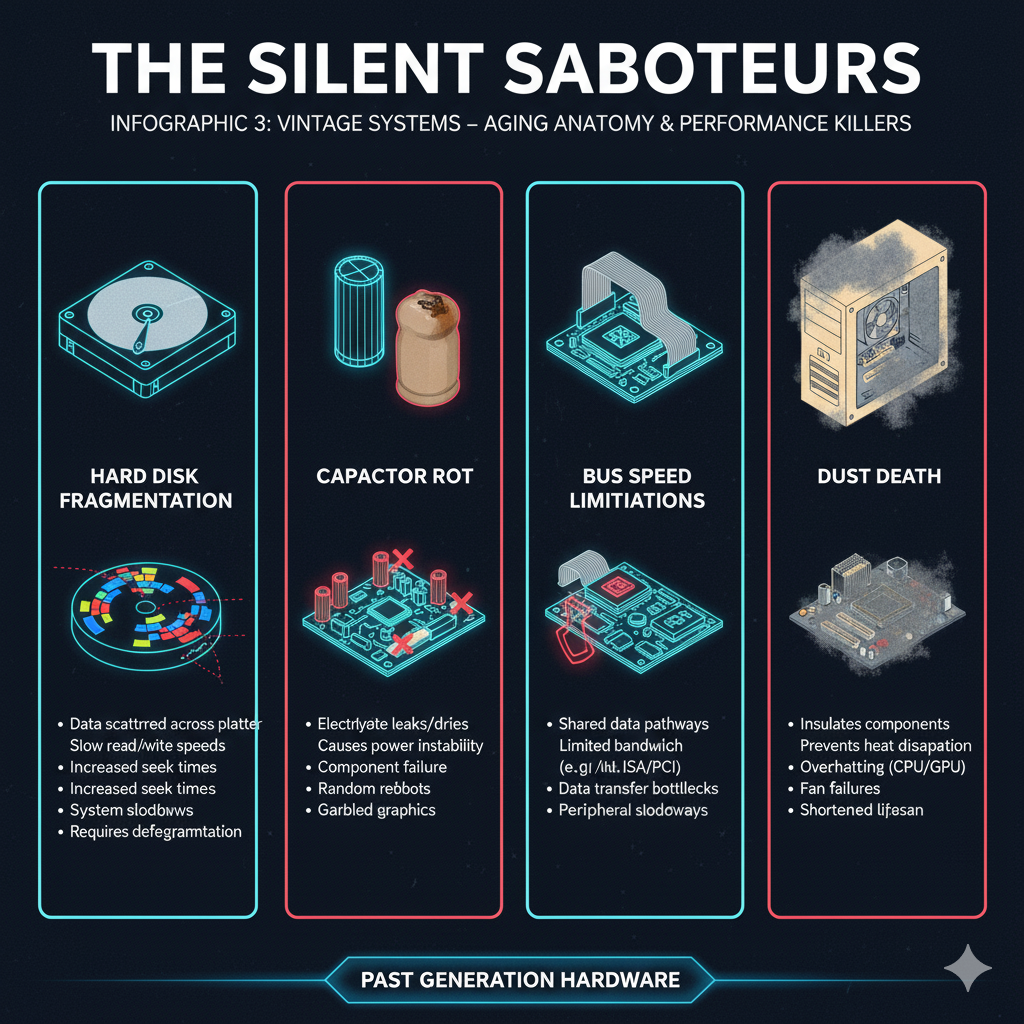
The Analog Failures: Capacitors and Power Supplies
The “Capacitor Plague”
One of the most infamous hardware failures in computing history was the Capacitor Plague, a period between 1999 and 2007 where a large number of non-solid aluminum electrolytic capacitors, primarily from Asian manufacturers, failed prematurely [18].
These capacitors, which smooth out the electrical current delivered to the CPU and other components, would bulge, leak, and eventually burst.
The performance impact was immediate and severe: the system would suffer from unstable power delivery, leading to random reboots, system crashes, and an inability to maintain stable clock speeds.
This was a catastrophic hardware failure that rendered countless motherboards and graphics cards unusable, demonstrating how a single, seemingly minor component can cripple an entire system [19].
Power Supply Unit (PSU) Degradation
The Power Supply Unit (PSU) in a vintage PC was a ticking time bomb of performance loss.
PSUs use electrolytic capacitors, which have a finite lifespan.
Over time, the electrolyte inside the capacitors dries out, reducing their capacity to filter and stabilize the power [20].
A degraded PSU delivers dirty power—voltage fluctuations and ripple—to the sensitive components of the system.
This instability can cause intermittent errors, data corruption, and system crashes.
Even before total failure, the poor transient response of an aging PSU can cause the system to become unstable under load, effectively limiting the maximum performance the system can achieve [21].
Mechanical and Magnetic Woes
Hard Disk Drive (HDD) Fragmentation and Head Wear
The performance of a traditional Hard Disk Drive (HDD) is fundamentally limited by the physical movement of its read/write heads.
When a file is written to an HDD, it is often scattered across non-contiguous sectors on the platter, a phenomenon known as fragmentation [22].
To read a fragmented file, the drive head must physically jump across the platter multiple times, increasing the seek time and dramatically reducing the data transfer rate.
This mechanical process of seeking data is the primary reason older systems slowed down over time.
While software defragmentation could temporarily fix the issue, the underlying hardware limitation—the speed of the mechanical arm—remained the ultimate performance bottleneck [23].
Bus and Interface Limitations
The speed of data transfer in older systems was constrained by the bus architecture itself.
The transition from Integrated Drive Electronics (IDE), also known as Parallel ATA (PATA), to Serial ATA (SATA) was a direct response to this hardware limitation.
PATA used a wide, parallel ribbon cable, which was susceptible to signal degradation and limited to a maximum theoretical throughput of 133 MB/s.
The physical design of the bus was the bottleneck.
SATA, with its thin, serial cable, offered a cleaner signal and higher speeds (up to 600 MB/s for SATA III), fundamentally unlocking higher performance for storage devices [24].
The performance of a legacy system was often capped not by the CPU, but by the speed of the bus connecting the components.
From Exascale to E-Waste: A Universal Lesson in Hardware Longevity
The journey from the exotic, liquid-cooled AI clusters of today to the dusty, capacitor-plagued PCs of yesterday reveals a profound and universal truth: performance is a constant battle against physics and entropy.
Whether it is the thermal limits of a 3nm AI chip, the wear-leveling algorithms of a modern NVMe drive, or the mechanical friction of a spinning hard disk, hardware issues are the ultimate, silent saboteurs of speed.
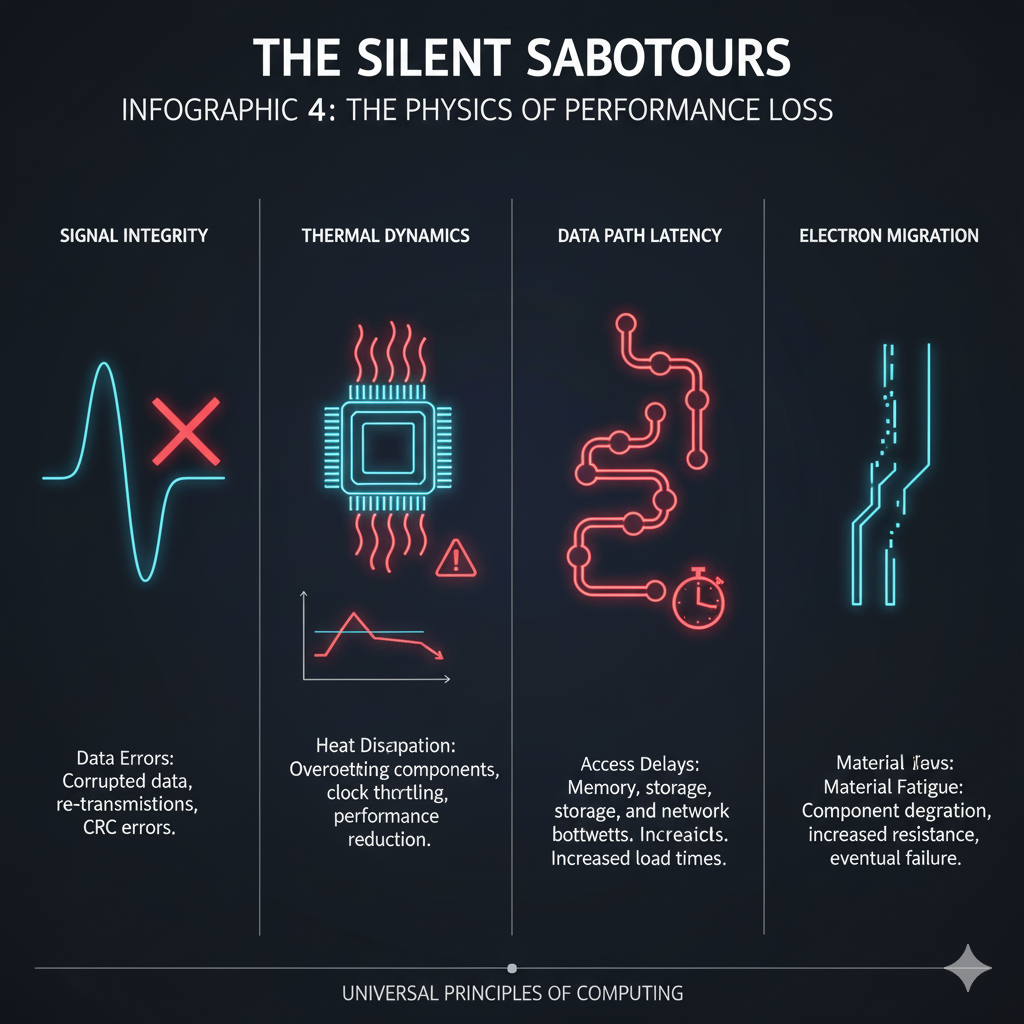
The nature of the problem changes with the era—from the data-starvation of HBM to the power instability of a bulging capacitor—but the effect is the same: a system that cannot operate at its full potential.
Understanding these hardware-centric bottlenecks is the first step toward mitigation.

References
[1] The Unseen Enemy: Why Hardware is the Ultimate Performance Bottleneck – Internal Synthesis
[2] The HBM Bottleneck: Why Real-Time Flow Data Matters Now – Exponential Tech
[3] AI’s Rapid Growth: The Crucial Role Of High Bandwidth Memory – SemiEngineering
[4] Scaling the Memory Wall: The Rise and Roadmap of HBM – SemiAnalysis
[5] Do I need InfiniBand for distributed AI training? – RunPod
[6] What is the Difference Between NVLink and InfiniBand? – JarvisLabs AI
[7] How PCIe Lane Allocation Impacts GPU and Storage Performance – HP Tech Takes
[8] Impact of GPU PCI-e Bandwidth on Content Creation Performance – Puget Systems
[9] Understanding the Critical Role of Bad Block Management – Exascend
[10] Write amplification – Wikipedia
[11] The CPU Cache Miss That’s Slowing Every Web Application – Medium
[12] Types of Cache Misses – GeeksforGeeks
[13] Does old thermal paste affect a PC’s performance? – Quora
[14] How Often Should You Replace Thermal Paste? – Mwave Blog
[15] My CPU is throttling due to high VRM temperatures, should… – Reddit
[16] How Write Amplification Impacts SSD Performance – Chat2DB AI
[17] RAM Timings and XMP/EXPO Profiles – Internal Synthesis
[18] Capacitor plague – Wikipedia
[19] The early 2000s capacitor plague is probably not just a… – Ars Technica
[20] The Top 10 Warning Signs of Power Supply Aging and In… – Gamemax PC
[21] How power supply aging affects your computer’s efficiency – LinkedIn
[22] Hard Drive Defragmenting: What Is It and Should You Do It? – Seagate
[23] Disk Fragmentation and System Performance – Microsoft Tech Community
[24] IDE/PATA vs. SATA – Internal Synthesis