

Introduction: The Chaos of the Unsystematic Fix
Every user, from the home enthusiast to the seasoned IT professional, has experienced the sheer frustration of a technical problem.
The screen freezes, the network drops, or the application crashes—and the immediate, often panicked, reaction is to try a series of random fixes: rebooting, unplugging, or frantically searching for a quick-fix forum post.
This approach, while occasionally successful, is a recipe for wasted time, recurring issues, and a deep sense of technical anxiety.
The difference between a technician who struggles and one who excels is not merely knowledge, but the systematic problem-solving approach they employ.
This methodology is a universal language for diagnosing and resolving faults, applicable whether you are debugging a complex software application, fixing a faulty network connection, or replacing a piece of hardware.
This guide will walk you through the structured, creative, and universally applicable framework that turns troubleshooting from a chaotic guessing game into a predictable, repeatable science.

Part I: The Universal Six-Step Systematic Methodology
The foundation of all effective technical troubleshooting is a structured, multi-step process.
This methodology, often championed by organizations like CompTIA, ensures that no critical step is missed, that solutions are based on evidence, and that the fix is permanent [1].
Mastering these six steps is the key to transforming your approach to any technical challenge.
Step 1: Identify the Problem
The first and most crucial step is to move beyond the symptom and define the actual problem.
This requires gathering information from the user, the system, and the environment.
Questioning the User:
A good troubleshooter acts as a detective, asking open-ended questions like: “What has changed since the last time it worked?” and “When exactly did the problem start?”
Documenting the symptoms, error messages, and the sequence of events that led to the failure is paramount.
System Information:
Check logs, event viewers, and diagnostic tools.
The system often leaves a trail of breadcrumbs—a critical error code or a repeated failure message—that points directly to the root cause.
Step 2: Establish a Theory of Probable Cause
Once the symptoms are clear, the next step is to hypothesize the most likely cause.
This is where experience and knowledge come into play, but even a novice can use the principle of “Least Likely to Most Likely” or “Outside-In” thinking.
Start with the simplest, most common possibilities (e.g., “Is it plugged in?” or “Is the cable loose?”) before moving to complex software bugs or hardware failures.
If a user reports a slow network, a probable cause theory might be “The router is overloaded” or “A recent software update is conflicting with the network driver.”
Step 3: Test the Theory to Determine the Cause
A theory is useless until it is tested.
This step involves creating a controlled experiment to confirm or deny your hypothesis.
If your theory is “The network cable is faulty,” the test is simple: replace the cable.
If the problem is resolved, the theory is confirmed.
If the problem persists, the theory is disproved, and you must return to Step 2 to establish a new theory.
This iterative process of elimination is the core of systematic troubleshooting.
Step 4: Plan of Action and Implement the Solution
Once the root cause is confirmed, a plan of action must be developed.
This plan should be documented and should include a clear path for reversal, or a backout plan, in case the solution introduces new problems.
Implementation should be done methodically, one change at a time, to isolate the effect of the fix.
For example, if the solution is a driver update, the plan should be: 1) Download the correct driver, 2) Create a system restore point (backout plan), 3) Install the driver, and 4) Reboot.
Step 5: Verify Full System Functionality and Implement Preventive Measures
The problem may be gone, but is the system truly fixed?
Verification involves testing not just the immediate fix, but all related system functions.
If you fixed a network issue, check local file access, internet browsing, and printing.
This step also includes implementing preventive measures to ensure the problem does not immediately return, such as scheduling automatic updates or training the user on best practices.
Step 6: Document Findings, Actions, and Outcomes
Documentation is the final, and often most neglected, step.
A detailed record of the symptoms, the theories tested, the final solution, and the preventive measures is invaluable.
It creates a knowledge base for future issues, helps track recurring problems, and provides a clear audit trail for compliance and management.
Part II: The Creative Application of Systematic Thinking
While the six steps provide the structure, the creative element lies in applying them to diverse technical domains.
Different problems require different diagnostic tools and mental models.
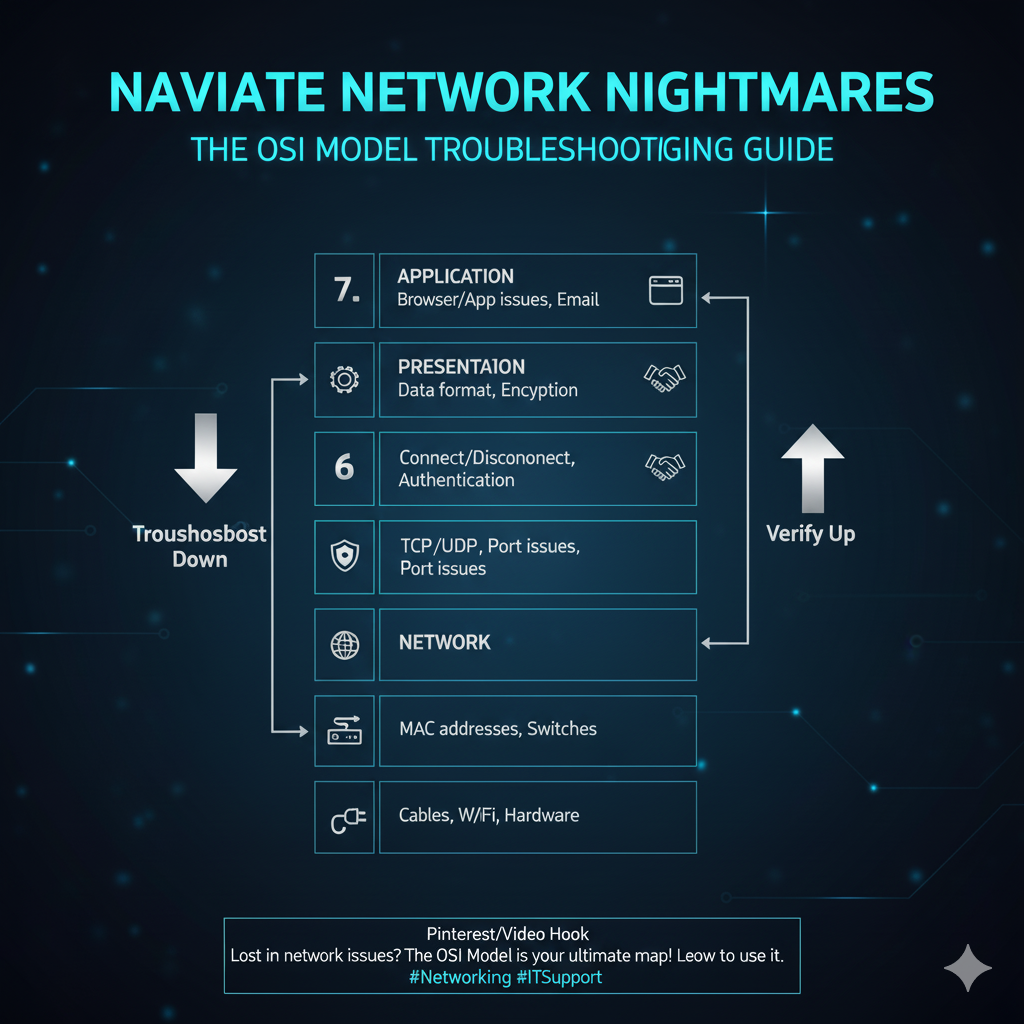
Troubleshooting Networking: The OSI Model as Your Diagnostic Map
Networking issues are perhaps the most complex because they involve multiple layers of abstraction.
The Open Systems Interconnection (OSI) Model is the ultimate systematic tool for network troubleshooting [2].
It divides the network communication process into seven distinct layers, allowing the troubleshooter to isolate the fault to a specific area.
The “Bottom-Up” Approach:
This is the most common and effective strategy.
You start at Layer 1 (Physical) and work your way up.
If Layer 1 is good (cable is plugged in, link lights are on), you move to Layer 2 (Data Link) to check MAC addresses and switches.
If Layer 3 (Network) is failing, you check IP addresses and routing tables.
This method ensures you don’t waste time debugging a complex application (Layer 7) when the simple cable (Layer 1) is the culprit.
The “Divide and Conquer” Approach:
If you have a general idea of the problem, you can start in the middle, often Layer 3 (Network).
If a ping to a remote server fails, you know the problem is at Layer 3 or below.
If the ping succeeds, you know the problem is at Layer 4 (Transport) or above, and you can focus your efforts there.
| OSI Layer | Common Problem | Systematic Test |
|---|---|---|
| Layer 1 (Physical) | Faulty cable, disconnected port, bad transceiver. | Check link lights, replace cable, use a cable tester. |
| Layer 2 (Data Link) | Incorrect VLAN assignment, MAC address conflict, spanning tree loop. | Check switch port status, examine MAC address table. |
| Layer 3 (Network) | Incorrect IP address, routing table error, firewall blocking ICMP. | Use ping, traceroute, and check router configuration. |
| Layer 4 (Transport) | Port blocked by firewall, service not listening (e.g., web server down). | Use telnet or netstat to check port connectivity. |
| Layer 7 (Application) | Incorrect URL, application configuration error, outdated browser. | Check application logs, clear browser cache, test with a different client. |
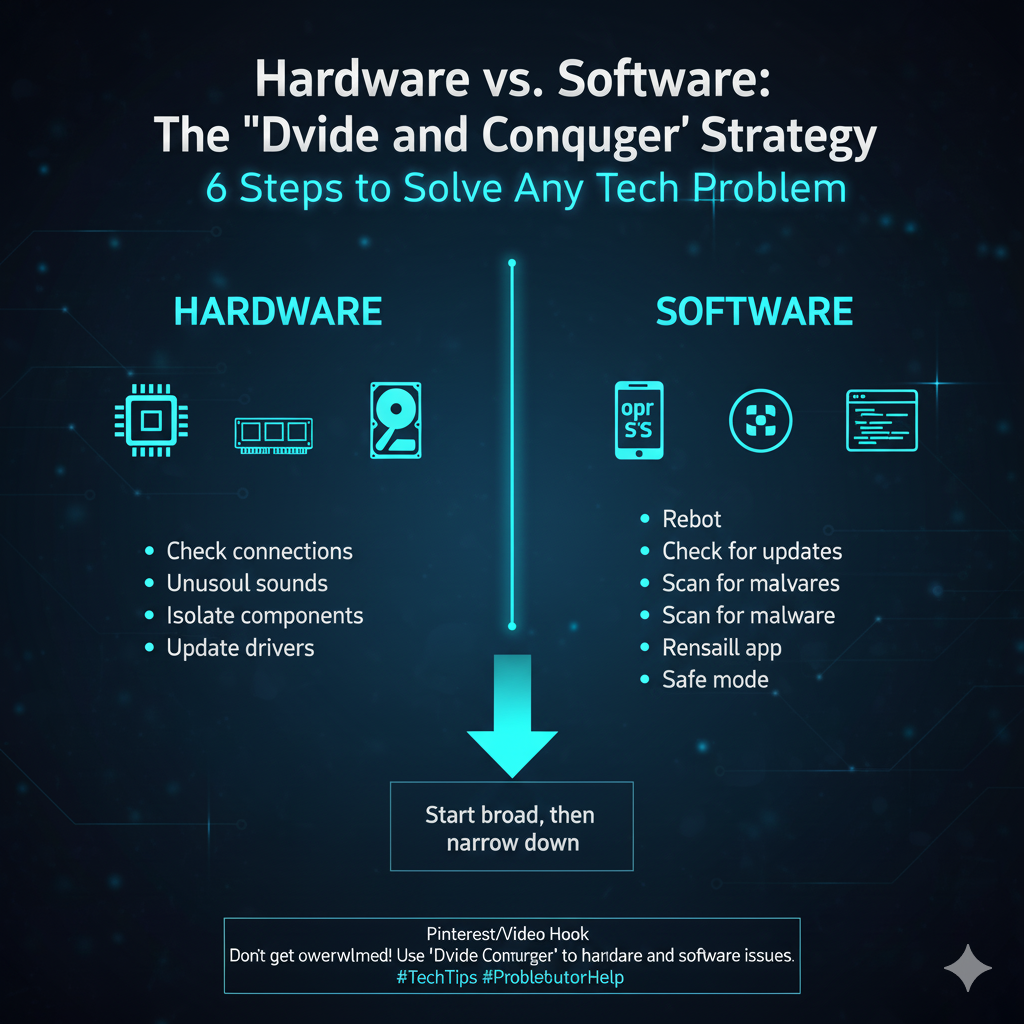
Troubleshooting Hardware: The Principle of Substitution
Hardware troubleshooting is often the most straightforward application of the six-step process, relying heavily on the Principle of Substitution.
Once a theory is established (e.g., “The power supply unit (PSU) is failing”), the systematic test (Step 3) is to substitute the suspected component with a known good one.
If the problem is resolved, the original component is confirmed as the cause.
If the problem persists, the theory is disproved, and the troubleshooter moves on to the next most likely component, such as the RAM or the motherboard.
This is a pure form of the elimination process.
Troubleshooting Software: The “Configuration vs. Code” Divide
Software issues can be the trickiest, as they often involve a complex interplay between the operating system, application code, and user configuration.
The systematic approach here is to first determine if the issue is a configuration problem or a code problem.
Configuration Issues:
These are often the result of user error, incorrect settings, or a corrupted profile.
Systematic tests include: running the application as a different user, resetting the application’s settings to default, or reinstalling the application without migrating old settings.
Code Issues:
These are genuine bugs in the application itself.
The systematic approach here involves checking for patches, updates, or known issues on the vendor’s support site.
If the issue is new, the troubleshooter must gather detailed logs and steps to reproduce the error (Step 1) before escalating the issue to a developer.
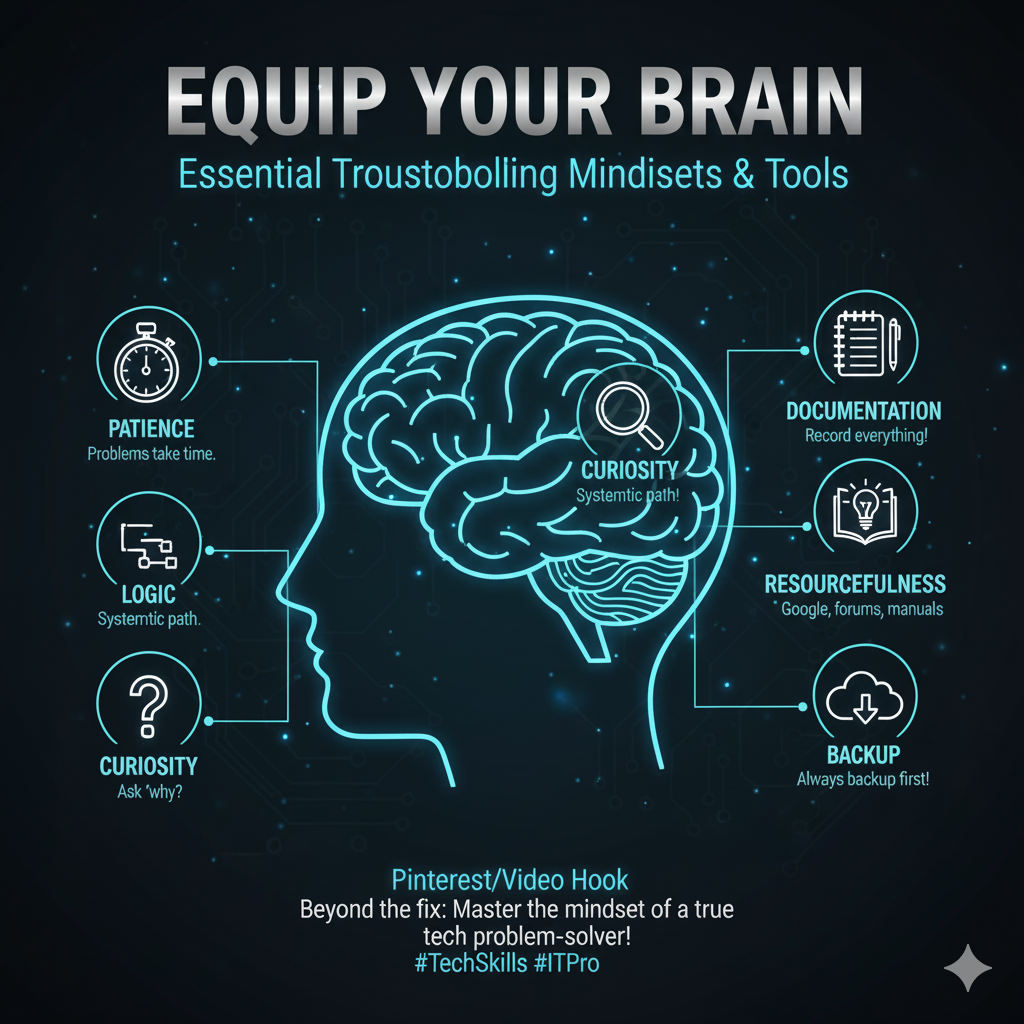
Part III: Cultivating the Creative Troubleshooting Mindset
The systematic process is the map, but the mindset is the compass.
Effective troubleshooting requires more than just following steps; it demands a blend of creativity, skepticism, and patience.
The Power of Skepticism: Trust, But Verify
A common pitfall is taking information at face value, especially from the user.
The user may say, “I didn’t change anything,” but a systematic troubleshooter knows that a change, however small or unintentional, is the most likely cause of a new problem.

The creative troubleshooter maintains a healthy skepticism, always verifying the user’s report with system diagnostics and log files.
Never assume a component is working just because it looks like it is; always test it.
Thinking Outside the Box: The Environmental Factor
Sometimes, the problem is not the technology itself, but the environment it operates in.
A systematic approach must expand its scope to include external factors.
For example, a sudden, intermittent network failure might be caused by a nearby industrial machine powering on (electromagnetic interference), or a server overheating due to a failed air conditioning unit.
The creative element is the ability to connect seemingly unrelated events—the flickering light and the dropped connection—into a single, coherent theory.
The Documentation Feedback Loop
The final step of documentation (Step 6) is not an endpoint; it is the beginning of the next troubleshooting cycle.
Every documented fix enriches the troubleshooter’s knowledge base, making the next “Establish a Theory” (Step 2) phase faster and more accurate.
This feedback loop is what separates a good troubleshooter from a great one—the great one has a constantly growing, self-correcting system of knowledge.
Conclusion: From Chaos to Confidence
Technical problems are an inevitable part of the digital world.
However, the anxiety and wasted time associated with them are not.
By adopting the Universal Six-Step Systematic Methodology, you gain a powerful, repeatable framework for solving any issue.
By creatively applying models like the OSI Model and principles like Substitution and Divide and Conquer, you can quickly isolate the root cause, whether it lies in a tangled network cable, a failing hard drive, or a corrupted software setting.
Embrace the systematic approach, cultivate a mindset of patient skepticism, and you will not only fix the problem but also gain the confidence to face any technical challenge the future may hold.
References:
- [1] CompTIA. Use a Troubleshooting Methodology for More Efficient IT Support.
- [2] Petri. How to use the OSI Model for Network Troubleshooting.