

Edge computing is rapidly transforming the digital landscape. 🌐
By pushing data processing closer to where data is created, businesses are unlocking unprecedented speeds. 🚀
This shift reduces latency for critical applications like autonomous driving and industrial IoT. 🏭
However, decentralizing infrastructure comes at a significant cost. 💰
We are moving away from the controlled, stable environment of centralized data centers.
We are moving into the chaotic, unpredictable world of distributed networks.
In this new paradigm, failures are not an anomaly; they are a given. 📉
Understanding and optimizing for these edge computing errors is crucial for system stability.
If you ignore the reality of distributed failures, your edge deployment will likely fail. 💥
This article will dive deep into the types of errors inherent in edge computing and provide actionable strategies for optimization.
The Inevitability of Errors at the Edge
Why is edge computing so prone to errors compared to traditional cloud computing? 🤔
The fundamental issue lies in the physical reality of distributed systems.
A centralized data center is a fortress of redundancy, highly reliable networking, and controlled temperatures. 🏰
An edge node might be a ruggedized server sitting on a dusty factory floor. 🌬️
It might be a gateway mounted on a 5G tower exposed to the elements. ⛈️
These environments are inherently hostile to sophisticated IT equipment.
Furthermore, the network connections linking these nodes to the core cloud are often unreliable. 📶
They rely on cellular networks, satellite links, or spotty Wi-Fi, all of which suffer from intermittent drops.
When you distribute compute, you also distribute the surface area for things to go wrong. 🛠️
According to leading tech analysis, the sheer volume of data generated at the edge is outpacing our ability to backhaul it to the cloud. 🌊
You can read more about the general challenges of distributed systems in this insightful article from the Amazon Builders’ Library.
The key takeaway is that we cannot design edge systems assuming perfect conditions.
Common Types of Edge Computing Errors
To optimize for distributed networks, we first need to categorize the errors we face. 🧐
These aren’t just simple software bugs; they are systemic issues related to the architecture.
- Network Partitioning: This occurs when a group of edge nodes loses connectivity to the main cluster or the central cloud. 💔 They become isolated islands, unable to synchronize data or receive updates.
- Latency Spikes: While edge aims to reduce average latency, network congestion or local resource contention can cause sudden, massive spikes in response time. 📈 This can break real-time applications.
- Resource Constraints: Edge devices often have limited CPU, memory, and storage compared to cloud servers. 💾 Running heavy AI models on the edge can lead to Out-Of-Memory (OOM) errors or thermal throttling.
- Data Synchronization Conflicts: When multiple edge nodes modify the same data while disconnected, reconnecting creates conflicts. ⚔️ Determining the “source of truth” becomes incredibly difficult.
- Security Breaches at the Perimeter: Physical security is lower at the edge. 🔓 An attacker gaining physical access to a node can introduce malicious data or disrupt the local network.
These errors highlight the fragility of distributed environments. 🧊
A famous concept in computer science sums this up perfectly.
The Fallacies of Distributed Computing
“The network is reliable. Latency is zero. Bandwidth is infinite. The network is secure. Topology doesn’t change. There is one administrator. Transport cost is zero. The network is homogeneous.” – (These are false assumptions that lead to failures.) 💡
Instead of trying to prevent every failure, we must build systems that recover gracefully. 🌿
Optimizing for Resilience: Designing for Failure
Optimization in edge computing doesn’t just mean making things faster. 🏎️
It means making things more resilient.
We need to apply specific software design patterns that handle instability automatically. 🤖
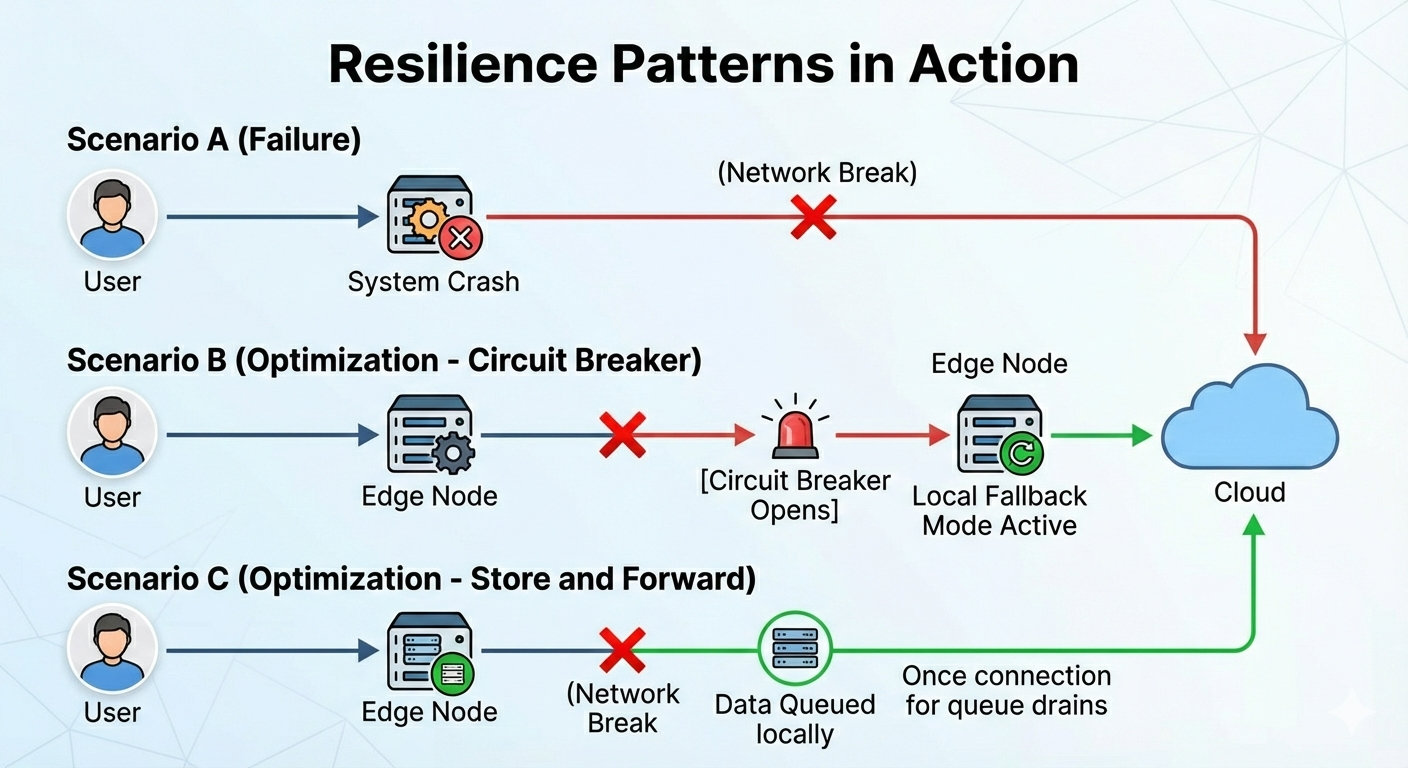
Implementing Circuit Breakers
Imagine an edge application trying to send sensor data to a cloud database that is currently offline. 🚫
Without protection, the application will keep trying, consuming resources and eventually crashing the local node.
A “Circuit Breaker” pattern detects repetitive failures. ⚡
After a certain threshold of errors, the circuit “opens,” and the application immediately stops trying to reach the failed service.
Instead, it switches to a fallback mechanism, such as caching the data locally. 📦
After a set timeout, the circuit allows a few test requests through to see if the service has recovered.
This prevents cascading failures across your distributed network.

The “Store and Forward” Mechanism
Network partitions are inevitable. 🤷♂️
Edge nodes must be capable of operating autonomously for extended periods. 🏝️
The “store and forward” technique is essential here.
When connectivity to the cloud is lost, data should be queued securely on local storage. 🔒
The edge node continues its primary function using locally cached data and models.
Once connectivity is restored, the queued data is asynchronously transmitted to the central system. 📤
For an excellent overview of cloud design patterns that apply to the edge, check out Microsoft Azure’s guidance on resiliency.
| Feature | Traditional Centralized Approach | Optimized Edge Approach |
|---|---|---|
| Network Assumption | High Reliability, Low Latency | Intermittent, Variable Latency |
| Error Handling | Fail Fast, Alert Admin | Degrade Gracefully, Self-Heal |
| Data Connectivity | Always Connected | Store and Forward Capability |
| State Management | Strong Consistency (ACID) | Eventual Consistency (BASE) |
The Challenge of Data Synchronization
Keeping data consistent across hundreds of dispersed nodes is perhaps the hardest challenge. 🤯
If two factories update their local inventory counts while disconnected from the internet, which count is correct when they reconnect?
Traditional databases relying on strong consistency (where everyone sees the same data at the same time) fail miserably at the edge. 📉
The latency required to lock data across a global network is simply too high.
To optimize for distributed networks, we must embrace “Eventual Consistency.” 🤝
This means we accept that data will be momentarily different across nodes, but it will eventually converge to a consistent state.
Technologies like Conflict-free Replicated Data Types (CRDTs) are emerging as powerful tools for this. 🛠️
They allow data to be updated independently on different nodes and guarantee that they can always be merged without conflicts later.
Leading database providers are now focusing heavily on these edge-native capabilities; see how DataStax discusses distributed databases at the edge. 💽
Security Errors act as Performance Bottlenecks
When we talk about edge computing errors, we often forget security failures. 🕵️♂️
But a compromised node is a failing node.
If an edge device is overwhelmed by a DDoS attack, it cannot process its legitimate workload. 🚫
A breach at a single edge node can compromise the entire distributed network if not isolated.
Optimizing for security is optimizing for performance and reliability.
The traditional “castle and moat” security model does not work when your assets are scattered everywhere. 🏰
You must adopt a “Zero Trust” architecture. 🚫 trust, ✅ verify.
Every single edge node must authenticate and authorize every request it receives, even from other nodes in the same network.
Data must be encrypted both in transit and at rest on the edge device. 🔑
Companies like Cloudflare are at the forefront of re-thinking security for the distributed edge; their perspective on edge security challenges is vital reading.
On Security Insight
“Security is not an add-on; it’s the foundation of a reliable distributed system. Without trust in your edge nodes, you have nothing.” 🛡️
Future-Proofing: AI for Predictive Error Detection
The future of edge optimization lies in automation. 🤖
Manual monitoring of thousands of edge devices is impossible for human teams. 😫
We need to use Artificial Intelligence and Machine Learning at the edge to predict errors before they occur. 🔮
By analyzing logs and performance metrics locally, an edge node can detect anomalies that precede a failure.
For example, a gradual increase in SSD latency might indicate an impending drive failure. 📉
The node could proactively request a workload migration to a healthy peer before it crashes completely.
This “self-healing” capability is the ultimate goal of optimizing distributed networks.
Optimizing for distributed networks means expecting errors and automating recovery. 🤖
It requires a fundamental shift in mindset from “preventing failure” to “managing failure.”
Organizations that master this will reap the massive benefits of edge computing. 💰
Those that try to force centralized paradigms onto the edge will be stuck in an endless cycle of firefighting. 🚒
For a broader look at where this technology is heading, check out IBM’s take on the future of edge computing.
By embracing resilience patterns, adopting eventual consistency, and prioritizing zero-trust security, you can turn the chaos of the edge into a competitive advantage. 🏆
Start optimizing today, because the edge is only getting bigger. 🌍